
Although they’ve been around in one form or another for many years, microservices are the new hotness in software development. There’s a good reason for this, as they provide many advantages for medium or large software systems.
At work, we’re refactoring a monolithic app into a slightly less monolithic app with some common functionality broken out into microservices. One of the key difficulties with decoupled microservices is tracking requests across a set of logs for each microservice that contribute to a single business transaction.
One way to tie the microservice activities together is to use a special ID for each transaction called a “correlation ID”. The correlation ID can be passed along in the chained call to each different service so that the thread of activity has a common reference token.
Correlation IDs should be a cross-cutting concern, and we wanted to keep them out of business logic, service URLs, and method signatures. These pieces helped us make that goal:
- To keep the IDs out of service URLs, we decided the correlation ID should be passed in an HTTP header we call “X-Correlation-ID”.
- Our microservices are all Java-servlet based, and servlet filters are ideal for inserting cross-cutting logic into a request.
- We’re using logback as the logging framework, and SLF4J’s MDC capability let us add thread-specific information into the logs at one specific point instead of throughout the code.
Implementing the filter and making the call into MDC was an easy 15 lines of code. What turned out to be more difficult was finding something that made a good default correlation ID when the client didn’t pass one to the microservice.
GUIDs were an obvious option. However, our APIs are only doing a few 100 thousands request a day, so we didn’t need a hash space that was 1038 entries big. Also, disk space is cheap but not free, working with huge log files is a support headache, we aren’t doing that many requests, and I didn’t want to add the extra 36 characters for a GUID to each log entry. We really just needed an id that was easy to generate, and wouldn’t have a hash collision more than every week or so.
My initial thought was just to use a random Java Integer. The hash space there is 232. A hash space of four billion should be safe from collisions if I only choose a few 100K random entries from it, right?
Well, no. Instead I ran into the Birthday Problem. The Birthday Problem is the likelihood that two people in a group will have the same birthday. With 365 different birthdays to choose from, it seems like that group would have to be pretty big before someone shares a birthday. However, probability tells us in a group of 23 people, odds are even that two of them will share the same birthday.
How does that work with 4 billion entries to choose from? With very large numbers, the probability that two entries in a set of k items chosen randomly from N items are identical can be approximated with this:
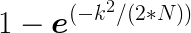
Plugging in k=300,000 service requests per day into this equation, and N=232, there’s 99.99% chance that our lightly used API will reuse a correlation id with just one day of traffic!
So a random integer is out. What about a random long? Plugging in k=300,000, and N=264, the likelihood that we’ll have a collision in a day is .00000024%. That’s better! In fact, according to this equation, we can run a whole year before chances of a collision go up to 0.03%.
Note that pseudo-random number generation has some inadequacies that might make this approach unsuitable for your application. Pulling 8 bytes at a time to get a Long may cause the returned values to “fall into the planes“. However, simple tests show that I can typically pull over 400,000,000 values without collision. In fact, when testing I didn’t see a collision, my tests just run out of heap space to store the membership sets.
As I mentioned above, disk space is an issue, and 18446744073709551616 is a lot of digits. I’d like to avoid putting 20-digit number in the log line, which is what would happen if we printed the long in base 10. I chose to encode the number as base 62, which is easy to implement, provides good compression for the number, and creates printable strings that are easy to find with grep. Base 62 encoding shortens that 20 digit string down to 11 characters. Almost 50% saved – not bad!
Putting it all together, here the Java filter that generates a correlation ID and base-62 encodes it:
public class CorrelationIdFilter implements Filter
{
private Random random = new Random();
private final int MAX_ID_SIZE = 50;
public void init(FilterConfig filterConfig) throws ServletException
{
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain filterChain)
throws IOException, ServletException
{
String correlationId = ((HttpServletRequest) request).getHeader("X-Correlation-Id");
correlationId = verifyOrCreateId(correlationId);
MDC.put("correlation-id", correlationId);
filterChain.doFilter(request, response);
}
public void destroy()
{
}
public String verifyOrCreateId(String correlationId)
{
if(correlationId == null)
{
correlationId = generateCorrelationId();
}
//prevent on-purpose or accidental DOS attack that
// fills logs with long correlation id provided by client
else if (correlationId.length() > MAX_ID_SIZE)
{
correlationId = correlationId.substring(0, MAX_ID_SIZE);
}
return correlationId;
}
private String generateCorrelationId()
{
long randomNum = random.nextLong();
return encodeBase62(randomNum);
}
/**
* Encode the given Long in base 62
* @param n Number to encode
* @return Long encoded as base 62
*/
private String encodeBase62(long n)
{
final String base62Chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
StringBuilder builder = new StringBuilder();
//NOTE: Appending builds a reverse encoded string. The most significant value
//is at the end of the string. You could prepend(insert) but appending
// is slightly better performance and order doesn't matter here.
//perform the first selection using unsigned ops to get negative
//numbers down into positive signed range.
long index = Long.remainderUnsigned(n, 62);
builder.append(base62Chars.charAt((int) index));
n = Long.divideUnsigned(n, 62);
//now the long is unsigned, can just do regular math ops
while (n > 0)
{
builder.append(base62Chars.charAt((int) (n % 62)));
n /= 62;
}
return builder.toString();
}
